Katib: Kubernetes Native 的超参数训练系统
这篇文章主要介绍了 Katib,一个由 NTT 贡献到 Kubeflow 社区的超参数训练系统。面向人群为对在 Kubernetes 上运行机器学习负载感兴趣的同学。
问题背景
在上一篇文章中,我主要介绍了 Kubeflow 社区中关于 TensorFlow 模型训练的支持工作,也就是 kubeflow/tf-operator。它使得用户能够在 Kubernetes 中运行 TensorFlow 的单机或者分布式训练任务,而它无法解决用户对于超参数训练的需求,于是 Katib 应运而生。
如果想了解 Katib,首先需要知道什么是超参数训练。@tobegit3hub 的贝叶斯优化: 一种更好的超参数调优方式一文对于其有一个比较好的介绍,这里引用一下:
首先,什么是超参数(Hyper-parameter)?这是相对于模型的参数而言(Parameter),我们知道机器学习其实就是机器通过某种算法学习数据的计算过程,通过学习得到的模型本质上是一些列数字,如树模型每个节点上判断属于左右子树的一个数,或者逻辑回归模型里的一维数组,这些都称为模型的参数。
那么定义模型属性或者定义训练过程的参数,我们称为超参数,例如我们定义一个神经网络模型有9527层网络并且都用RELU作为激活函数,这个9527层和RELU激活函数就是一组超参数,又例如我们定义这个模型使用RMSProp优化算法和learning rate为0.01,那么这两个控制训练过程的属性也是超参数。
显然,超参数的选择对模型最终的效果有极大的影响。如复杂的模型可能有更好的表达能力来处理不同类别的数据,但也可能因为层数太多导致梯度消失无法训练,又如learning rate过大可能导致收敛效果差,过小又可能收敛速度过慢。
那么如何选择合适的超参数呢,不同模型会有不同的最优超参数组合,找到这组最优超参数大家会根据经验、或者随机的方法来尝试,这也是为什么现在的深度学习工程师也被戏称为“调参工程师”。根据No Free Lunch原理,不存在一组完美的超参数适合所有模型,那么调参看起来是一个工程问题,有可能用数学或者机器学习模型来解决模型本身超参数的选择问题吗?答案显然是有的,而且通过一些数学证明,我们使用算法“很有可能”取得比常用方法更好的效果,为什么是“很有可能”,因为这里没有绝对只有概率分布,也就是后面会介绍到的贝叶斯优化。
也就是说,机器学习的模型本身有一些参数,这些参数的选择通过训练的方式获得一个最优解或者次优解的过程,就是超参数训练的过程。这个过程是一个黑盒的优化过程,我们对模型本身一无所知,也不能做任何假设。而且训练模型往往是一个比较昂贵的任务,要么会占用相当长时间的 CPU,要么会占用 GPU,所以我们并没有很多的尝试机会。因此我们要做的就是在有限的尝试次数中,尽可能确定一组输入,能得到尽可能好的输出。
相关工作
Google Vizier 是 Google 内部的机器学习超参数训练系统的一个子系统,有一篇论文详细介绍了其抽象以及架构设计:Google Vizier: A Service for Black-Box Optimization。Google Vizier 对超参数训练这一需求进行了比较好的领域抽象,并且支持多个参数搜索的算法。
@tobegit3hub 基于此实现了开源的实现 advisor,其采取了 clinet 与 server 的架构,并且提供了基础的 UI 界面。并且支持多个机器学习框架(如 TensorFlow, scikitlearn 等)。Cisco AI 也基于 Google Vizier 实现了自己的超参数训练工具 hyper-advisor-client。
Katib 介绍
Katib 也是对 Google Vizier 的开源实现,因此也遵循其中对问题的抽象模型:Study,Trial 和 Suggestion。
Trial 代表着一个由超参数的取值组成的列表,每个 Trial 都需要一次运行来得到这些超参数取值对应的结果。这里提到的运行就是一次训练的过程。Study 代表着在可行空间上运行的单个优化。每个 Study 都有一个配置,来描述可能取值的空间,超参数推荐算法等。此外,Study 包含一组 Trial,代表着算法在超参数集合中选取推荐值的多次尝试。如图所示,是创建一次 Study 并且进行 Trial 的验证的过程。
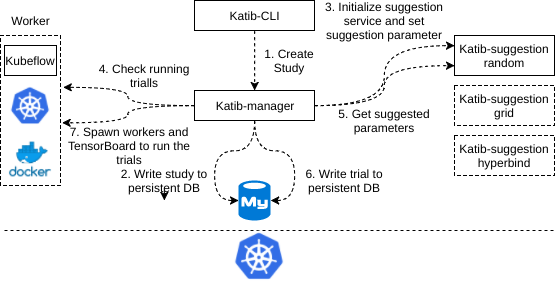
首先,用户会通过 katib-cli 创建一个新的 Study,这需要用户提供一份配置,下面是一个样例配置。目前配置中主要有两类参数,一类是 Study 本身需要的参数,比如使用的 Suggestion 算法,在此例中就是 random。另一类是运行时需要的一些参数,比如其中的 scheduler,就是在使用 Kubernetes 运行 Trial 时的一个参数,它决定这一 Trial 会被哪个调度器调度。
name: cifer10
owner: root
optimizationtype: 2
suggestalgorithm: random
autostopalgorithm: median
objectivevaluename: Validation-accuracy
scheduler: default-scheduler
image: mxnet/python
suggestionparameters:
-
name: SuggestionNum
value: 2
-
name: MaxParallel
value: 2
command:
- python
- /mxnet/example/image-classification/train_cifar10.py
- --batch-size=512
metrics:
- accuracy
parameterconfigs:
configs:
-
name: --lr
parametertype: 1
feasible:
min: 0.03
max: 0.07
-
name: --lr-factor
parametertype: 1
feasible:
min: 0.05
max: 0.2
-
name: --max-random-h
parametertype: 2
feasible:
min: 26
max: 46
-
name: --max-random-l
parametertype: 2
feasible:
min: 25
max: 75
-
name: --num-epochs
parametertype: 2
feasible:
min: 3
max: 3
随后,katib-manager 收到了来自 katib-cli 的创建 Study 请求后,会将 Study 的配置写入 SQL 数据库(目前为 MySQL),然后访问相应的 suggestion service 来初始化服务并且设置一些参数。接下来 katib-manager 会去对应的 worker 中检查已经运行的 Trial,以及成功了的 Trail,并且以此作为参数,通过 suggestion 服务来得到需要被运行 Trial,继而交给 worker 去运行。
在整个的工作流中,涉及到 katib-cli,katib-manager,suggestion 和 worker 等多个不同的组件。其中 katib-cli 是一个 CLI 工具,通过它,用户可以与 katib-manager 交互。katib-manager 之于 katib 就相当于 kube-apiserver 之于 Kubernetes,它是 katib 中最核心的一个组件。它会负责与其他各个组件交互,并且将结果写入数据库。suggestion 则是一个逻辑上的概念。它包含着很多不同的算法,而每一个算法都是以一个容器的方式独立运行,但所有的算法都会暴露同一端口,使用 suggestion 同一前缀,以便于服务发现。worker 与此类似,也是一个逻辑上的概念。Katib 在架构上支持不同的 worker 以适配不同的环境。
katib-cli,katib-manager 以及不同的 suggestion 算法服务,都是运行在不同的容器中的。所有调用,都是通过 GRPC 的方式进行。这使得 Katib 具有极好的扩展性。在添加新的算法支持时,Katib 可以不停机地进行。而且 worker 的接口使得 Katib 也可以轻易地接入新的云环境。
除此之外,Katib 支持的 Kubernetes worker 可以利用 Kubernetes 的集群能力将 Trail 的运行分布在不同的机器上,使得其真正地具有大规模超参数训练的可能,这也是目前其他同类型的系统支持地并不好的一点。
Katib 使用 modeldb 存储模型,Trail 与模型一一对应。Katib 将所有从 Trail 训练得到的模型存储在 modeldb,以方便管理和查看不同超参数训练出来的模型效果。这里有一个 demo,可以一观。
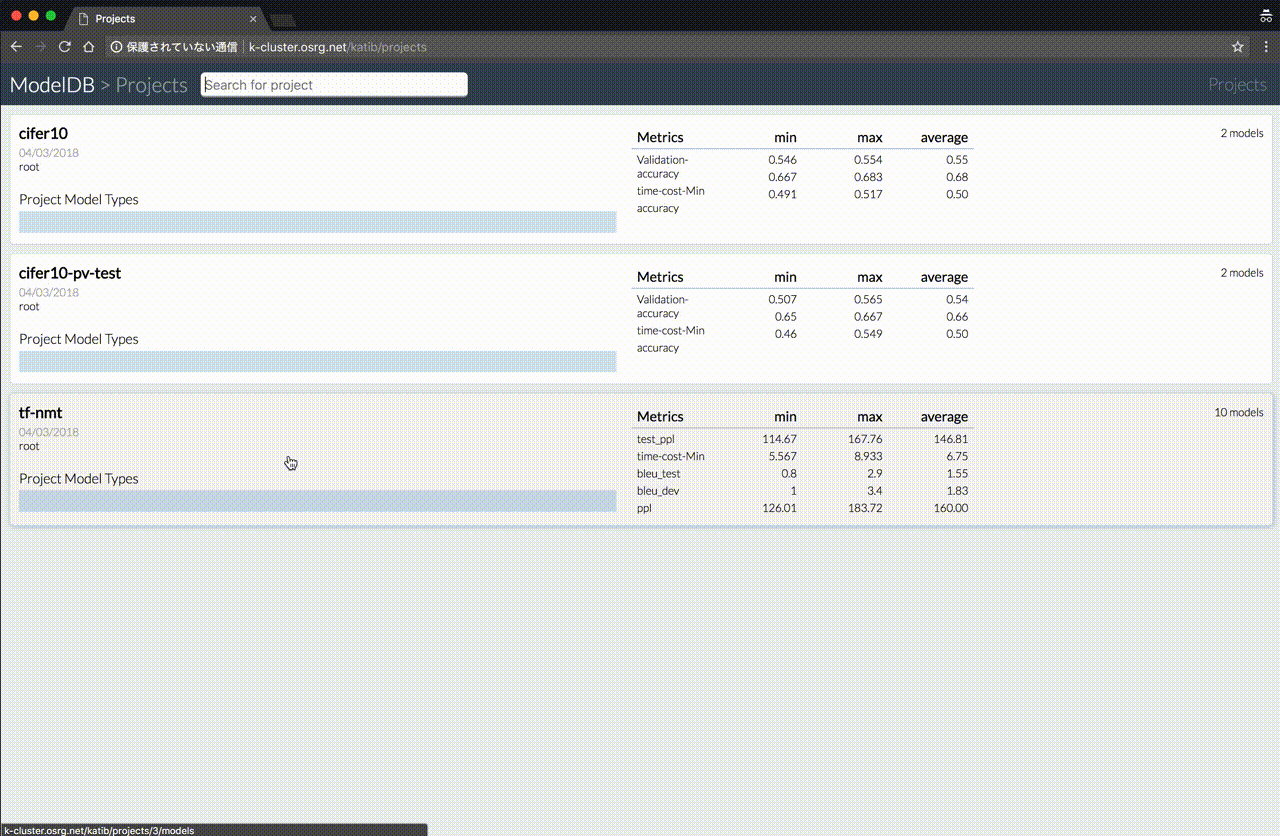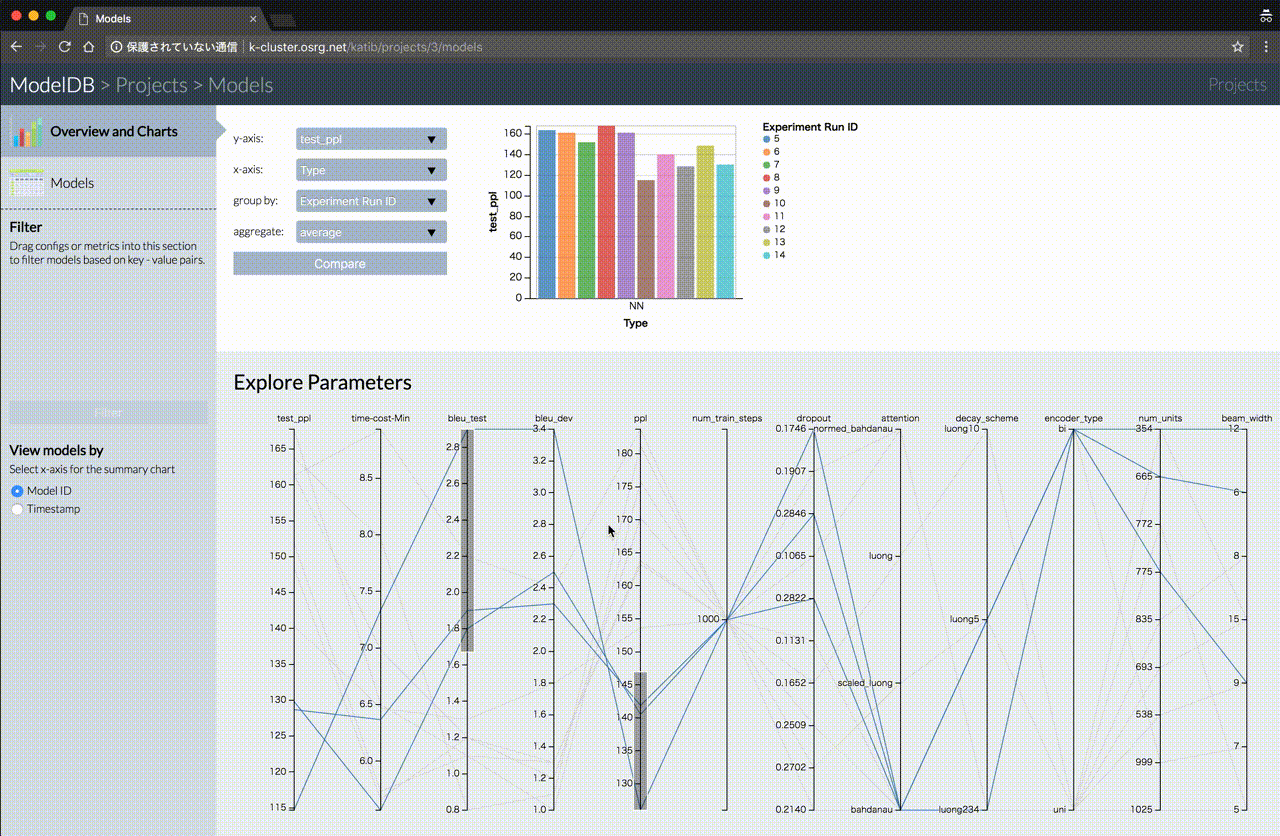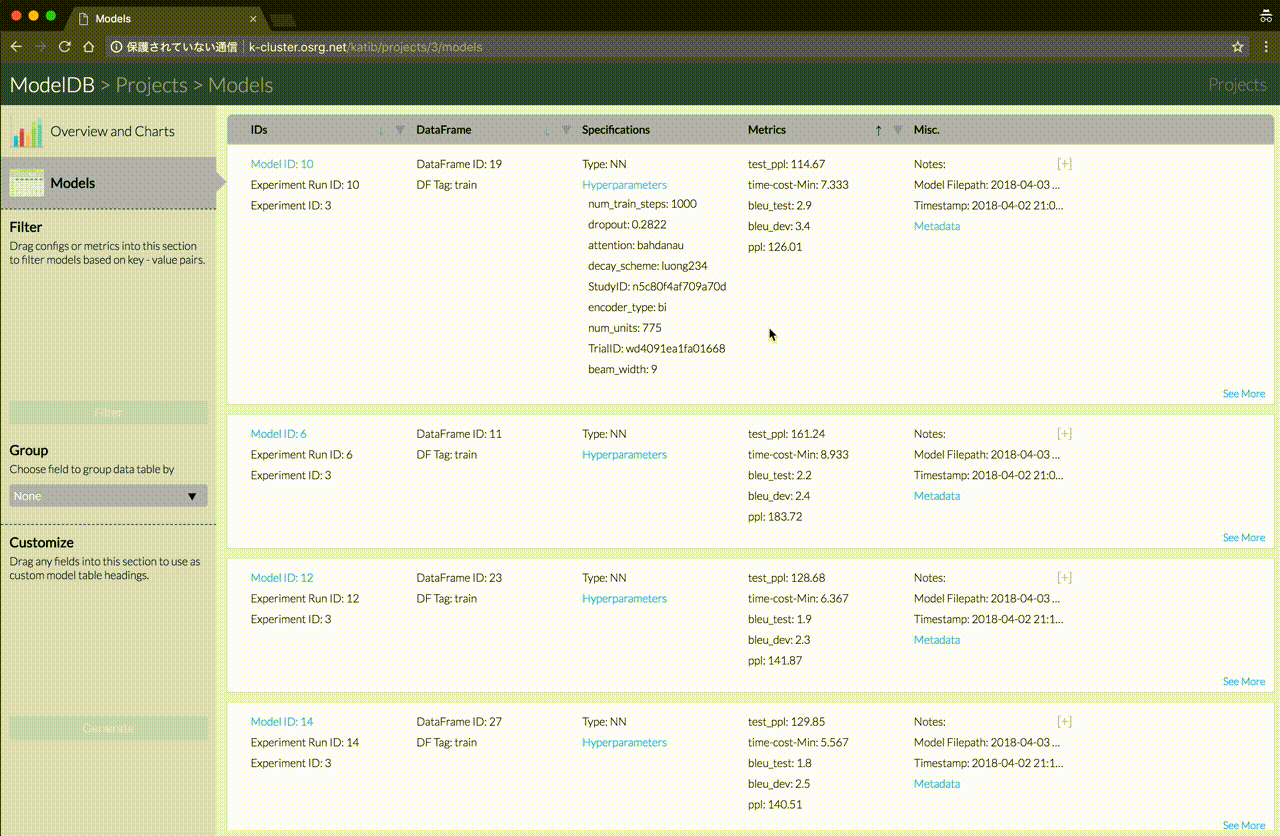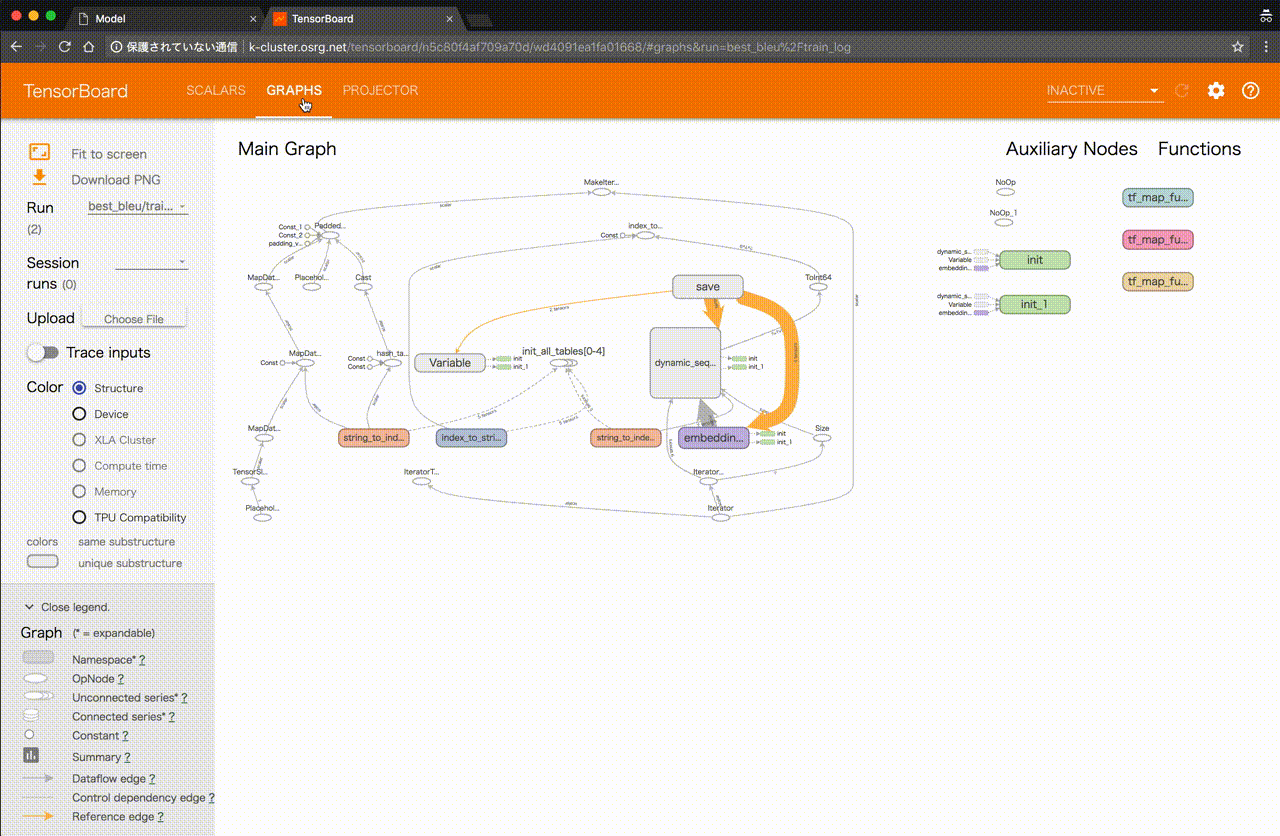
未来的工作与计划
在这篇文章中,我们介绍了 Katib 这一基于 Kubernetes 的超参数训练系统,并且阐述了其与其他系统相比的优劣。目前我们正在紧锣密鼓地开发新的特性与功能,这其中包括但不限于:
Early Stop 支持 这一特性能够节省集群的资源,提高参数寻找的效率。目前这一工作由 @YujiOshima 进行。
更多 Suggestion 算法支持 目前我们只支持三种较为简单的算法,分别是随机搜索,网格搜索和 Hyperband。因此我们正在着手实现贝叶斯优化等等算法。这一工作由 @libbyandhelen 进行。
与 Kubeflow 的集成 Katib 支持原生的 Kubernetes,对于运行 Trial 的容器的配置较为复杂。我们希望能够利用社区现有的 tf-operator 和 pytorch-operator 来提供对不同机器学习框架的支持。这一工作由 @gaocegege 进行。
支持 Neural Architecture Search (NAS) NAS 的支持是社区呼声比较高的需求,我们希望能够基于 Katib 的架构实现 NAS。目前这一工作由 @YujiOshima 进行。
以 CRD 的方式支持 Study 资源 目前 Katib 维护了自己的 CLI,以及配置文件格式。我们认为这可以被 Kubernetes CRD 替代。我们目前正在探索可否实现 katib controller 来替代 katib-cli 与 katib-manager。如此一来 Katib 的维护会更加简单。
与此同时我们也欢迎更多对超参数训练,以及神经网络模型搜索的同学为 Katib 贡献 :-) 欢迎加入我们的 Slack Channel,在这之前需要先通过这一邀请链接注册。
关于作者
@gaocegege,上海交通大学软件学院研究生在读,Kubeflow core approver
许可协议
- 本文遵守创作共享CC BY-NC-SA 3.0协议
- 网络平台转载请联系 marketing@dongyue.io