浅入了解容器编排框架调度器之 Kubernetes
Kubernetes 是由 Google 捐赠给 CNCF 的一个容器编排框架,也是目前应用最为广泛的编排框架之一。这篇文章是对 Kubernetes 1.8 中的 Scheduler(以下称为 kube-scheduler)的介绍,如果要阅读本文,需要对 Kubernetes 的基本概念如 pod, node 等有所了解。
调度过程
在读代码之前,先对 Kubernetes 整体的调度过程做一个简单的介绍。如果你对 Kubernetes 的调度过程已经熟悉的话,可略过不读。
Kubernetes 的调度的目的是把一个 pod 放在它最合适的 node 上去运行,所以调度的过程可以被理解为找一个 node,把 pod 放上去的过程。整个过程可以类比为喜闻乐见的相亲活动,pod 是相亲者,node 是所有可选的相亲对象,而 kube-scheduler 就像是相亲网站,它会负责根据相亲者的要求,找到与其要求最接近的相亲对象。当然这里也有一些不同点,比如每个 node 可以运行多个 pod,但是相亲者与相亲对象绑定以后应该是不能再跟别人进行喜闻乐见的相亲活动了/w
出于性能,可扩展性以及其他各个方面的考虑,Kubernetes 的调度分为两个过程,第一个过程叫做 Predicates,第二个过程叫做 Priorities。
在 Predicates 过程中,kube-scheduler 会先执行一系列被称为 predicate 的函数,过滤掉不符合硬性条件的 node。这个环节可以对应相亲活动中的硬条件过滤,比如你想找一个程序员,那相亲网站会帮你过滤掉所有不是程序员的选择。而所有通过了 Predicates 过程的 node,都会进入下一个过程。
在 Priorities 过程中,kube-scheduler 会将所有通过 Predicates 过程的 node 根据自己的标准打分,然后从中选择一个得分最高的 node,将其与 pod 绑定在一起,即在该 node 上运行此 pod。这就好比,相亲网站过滤好了潜在的相亲对象,会再帮你对他们做一个打分,然后推荐给你一个条件最好的给你。(不要问我为什么这么熟练)
文字性的叙述过于单调,这里用图来说明这个过程。在图中一共有 16 台服务器,有着不同的配置。
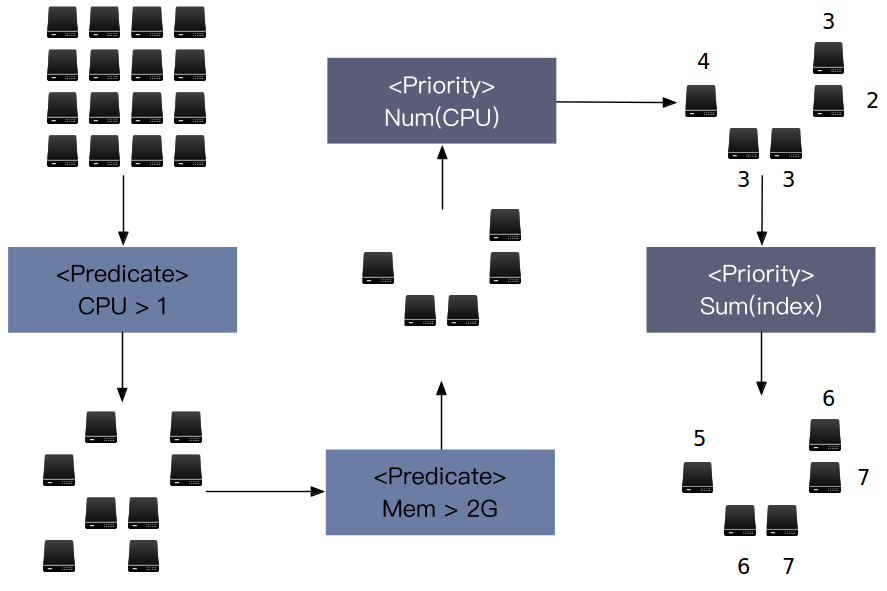
经过了两个 predicate 后,过滤掉了不满足条件的 node,剩下的 node 都足以运行 pod,这时候就需要 Priorities 过程来找到最适合的那个 node。经过两轮 priority 后,发现了一个最适合的 node,于是 pod 和 node 终于在一起了。在绝大多数情况下,调度就结束了。
这里特此说明,这些图只是为了说明调度的过程,Kubernetes 支持的 predicate 和 priority 的维度并不是 CPU 和 Memory。
代码编译
编译 kube-scheduler 只需要运行
make all WHAT=plugin/cmd/kube-scheduler
就可以了,编译后的结果会被放置在 ${KUBERNETES_PATH}/_output/bin/ 下。
浅入理解
接下来就进入了最激动人心的代码阅读部分。kube-scheduler 的入口是在 plugin/cmd/kube-scheduler/scheduler.go 中,因此如果要阅读调度的代码,从这里开始就可以了。
不过 main 函数只是告诉你他是怎么启动的,真正的逻辑是从 plugin/cmd/kube-scheduler/app/server.go#L68 开始的。在 Run 函数中,首先创建了一个 Kuberntes Clientset,这可以理解为是 kube-scheduler 跟 Kubernetes 进行交互的 client,通过它可以拿到集群上 node,pod 等等的信息。然后根据这个 client 创建出对 node 和 pod 等等资源的 informer,这里用了一点点的 trick,来规避 import cycle。以 node informer 的逻辑为例,其创建的逻辑在 staging/src/k8s.io/client-go/informers/core/v1/node.go#L47。Informer 有点像是观察者模式的样子,会 watch 一种资源的变化,这里水很深,代码挺复杂的,好奇的话建议仔细看看。在创建 kube-scheduler 的过程中,几乎所有的 informer(除了 pod informer),都是通过一个 factory 来做的,这样可以防止频繁地创建。之后就是 scheduler 去获取 leader 的地位,然后执行 plugin/pkg/scheduler/scheduler.go#L159 中的 run 函数,真真正正地开始提供相亲服务了。
而实际上,这个 scheduler 也只是一层抽象,真正的 scheduler 的算法,是由 plugin/pkg/scheduler/core/generic_scheduler.go 提供的。如果你想替换原本的调度算法,可以从这个地方入手,也可以自己重新写一个全新的 scheduler,然后在 pkg/scheduler/factory/factory.go#L708 直接修改创建的逻辑。
在真正的逻辑中,一共有这么两个比较重要的函数:Schedule,Preempt。分别对应着调度和抢占调度的逻辑。
先看 Schedule 函数,之前讲的 Predicates 和 Priorities 过程,就是在这个函数里进行的。在有了之前的积淀,这个函数其实很容易读懂。不过值得注意的是,在 Predicates 过程中,因为数据是没有依赖的,就是说检查每个节点是不是合格的节点其实是独立的事件,所以可以被并发来处理,在目前的实现中是会有 16 个独立的 worker 来处理所有的 Predicates 检查的。在 Priorities 过程中,数据不是完全独立的,因此完全并发的做法是行不通的,于是被实现成了 Map Reduce 的模式。可以不依赖其他的节点进行的计算,在 Map phase 来做,不能的就在 Reduce phase 来做。但是由于之前是完全单线程的实现,为了兼容性,目前在代码里可以看到单线程和并发的实现都存在在代码中。Map Reduce 模式的新实现是从 generic_scheduler.go#L404 开始的,Map phase 的做法跟之前的 Predicates 是一样的,而 Reduce 是单线程来做的。
值得注意的是,有一些 priority 函数不太适合用 Map Reduce 模式来进行处理,如果你感兴趣的话可以看看 issues#51455,这里有一些关于这些函数的讨论。
再看看 Preempt 函数,这是一个比较新的 feature,支持 Pod 的抢占,具体的设计可以参见 design proposal。大致的意思是说如果一个高优先级的 pod 没地方跑了,就杀掉一个在跑的低优先级的 pod,优先运行高优先级的 pod。在实现上,首先调度器会先去寻找那些可能运行这个 pod 的 node,如果 node 是因为一些诸如 selector 不 match 之类的问题被过滤掉了,那是无解的,但是如果是不是因为特别硬性的要求,而是因为资源不够运行这个 pod 之类的,那就列为潜在的合格 node。然后,调度器会在所有潜在的合格 node 上寻找可以被杀掉的 pod,如果不止一个 node 在杀死 pod 后可以满足要求,那就再经过一番选择,主要是选出优先级最低的 pod 所在的 node。选择的过程在 generic_scheduler.go#L501,并不难懂。
总体来说,我觉得读起来还是很简单的,本文就到此为止,系列下一篇应该是对 Nomad 的介绍,大概应该就是在最近吧。
许可协议
- 本文遵守创作共享CC BY-NC-SA 3.0协议
- 网络平台转载请联系 marketing@dongyue.io